

Chronos는 사전 훈련된 확률적 시계열 모델을 위한 간단하지만 효과적인 프레임워크입니다.
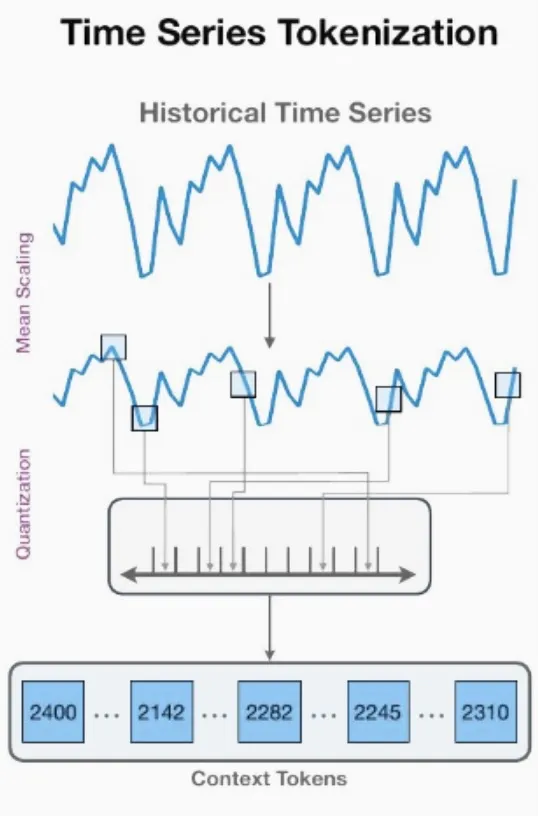
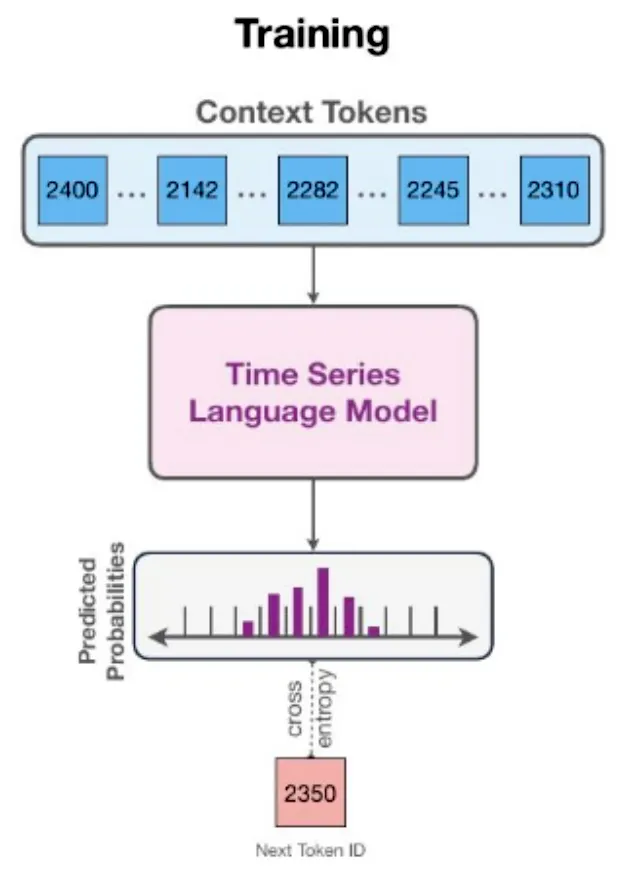
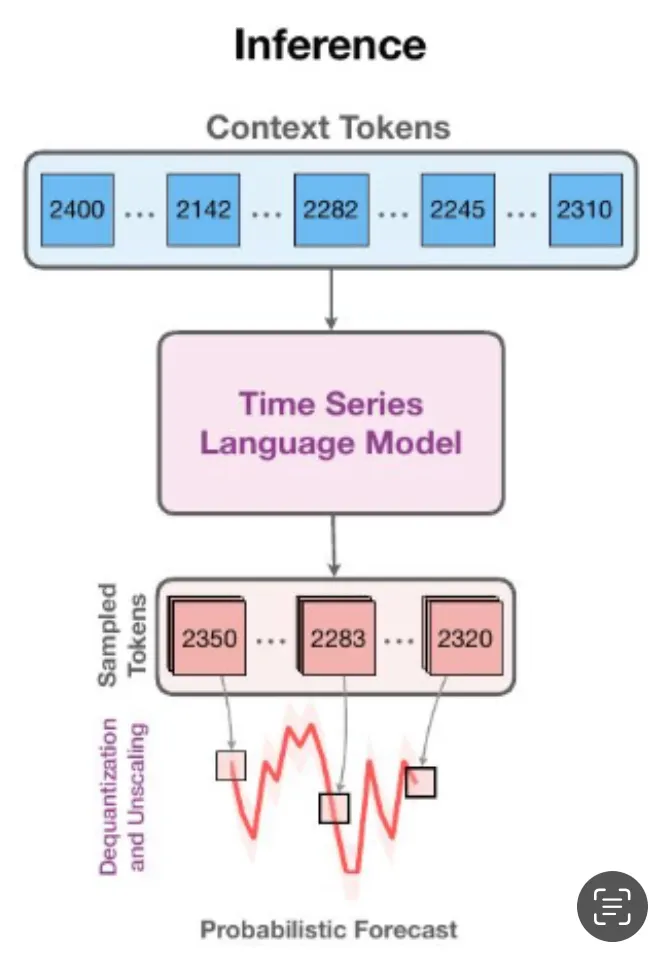
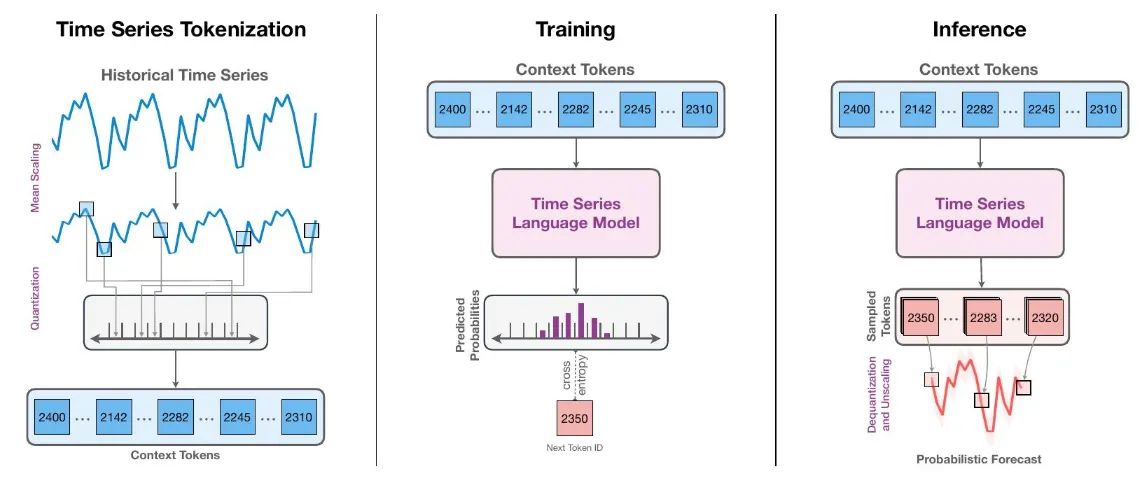
Chronos는 시계열 값을 스케일링과 양자화를 사용해 고정된 어휘집으로 토큰화하고, 이러한 토큰화된 시계열을 교차 엔트로피 손실을 통해 기존의 변환기 기반 언어 모델 구조에 훈련시킵니다.
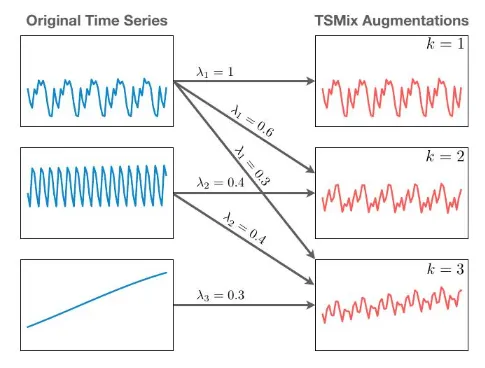
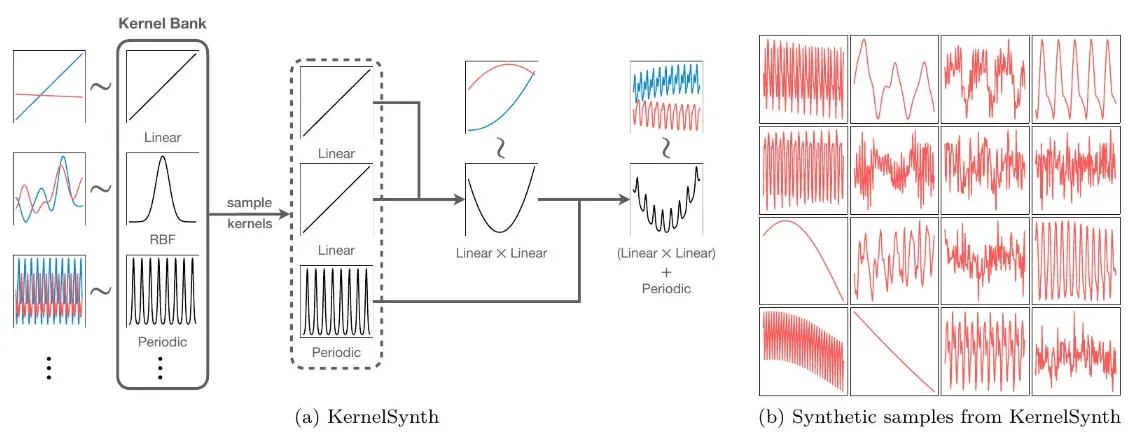
20M에서 710M에 이르는 T5 계열의 Chronos 모델을 대규모 공개 데이터셋 컬렉션과 일반화를 개선하기 위해 가우시안 프로세스를 통해 생성한 합성 데이터셋에 사전 훈련시켰습니다. 42개의 데이터셋으로 구성된 광범위한 벤치마크에서, 기존 로컬 모델과 딥러닝 통틀어, Chronos 모델이 훈련 데이터셋의 일부였던 데이터셋에서 다른 방법들을 크게 능가하고, 특정 데이터셋에만 훈련된 방법들과 비교했을 때 새로운 데이터셋에 대한 제로샷 성능이 비슷하거나 때로는 우수함을 보여줍니다.
Chronos 모델이 다양한 도메인의 시계열 데이터를 활용하여 보이지 않는 예측 작업에 대한 제로샷 정확도를 향상시킬 수 있음을 보여주며, 사전 훈련된 모델을 예측 파이프라인을 크게 단순화할 수 있는 유망한 도구로 위치시킵니다.



(b)
그림 16은 스케일링과 양자화 과정에서 발생하는 정밀도 손실을 보여줍니다.
a)에서, 데이터는 관찰마다의 단위 스파이크로 구성되며 (위에서 아래로), 여기서의 스케일은 입니다. 따라서 최대로 표현 가능한 값은 $15/n$이 됩니다. 인 경우, 모델은 스파이크를 적절히 포착할 수 없습니다(가장 위의 경우 제외). 왜냐하면 그 값이 토큰으로 정확히 표현되지 않기 때문입니다.
b)에서, 데이터는 만큼 상향 이동된 사인파입니다. 여기서의 스케일은 이며, 신호의 분산이 에 비해 점점 작아짐에 따라 토큰의 정밀도가 감소합니다.
간단히 말해서, 스케일링과 양자화 과정에서 데이터를 대표하는 토큰의 정밀도가 손실될 수 있으며, 이는 모델이 데이터의 특정한 패턴이나 변화를 정확히 포착하고 표현하는 데 제한을 줄 수 있습니다.