
Optimization via gradient descent
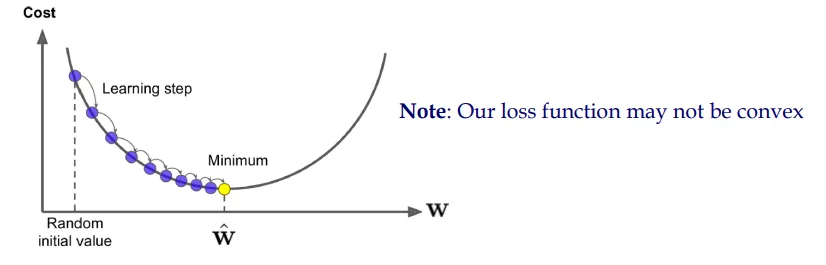

이 두 가지 업데이트 방정식은 신경망 학습에서 중요한 역할을 합니다. 첫 번째는 행렬 형태로 주어진 전체 가중치 벡터 또는 행렬의 업데이트를 나타내며, 두 번째는 단일 가중치 매개변수의 업데이트를 보여줍니다. 두 식 모두 비용 함수 \(J(\mathbf{w})\)의 그래디언트를 사용하여 가중치를 업데이트합니다. 여기서, \(\eta\)는 학습률(learning rate)이며, \(J(\mathbf{w})\)는 비용 함수(cost function) 또는 손실 함수(loss function)를 의미합니다.
행렬 형태의 업데이트 방정식
$$
\mathbf{w}^{(\text {new })}=\mathbf{w}^{(\text {old })}-\eta \nabla_{\mathbf{w}} J(\mathbf{w})
$$
이 방정식에서 \(\mathbf{w}^{(\text {old })}\)는 업데이트 전의 가중치를, \(\mathbf{w}^{(\text {new })}\)는 업데이트 후의 가중치를 나타냅니다. \(\nabla_{\mathbf{w}} J(\mathbf{w})\)는 비용 함수의 가중치에 대한 그래디언트(기울기 벡터)이며, 각 매개변수에 대한 손실 함수의 편미분을 포함합니다. 학습률 \(\eta\)는 이 그래디언트에 곱해져, 가중치 업데이트의 크기와 방향을 결정합니다. 이 과정은 비용 함수를 최소화하는 방향으로 가중치를 조정하는 경사 하강법의 한 형태입니다.
단일 매개변수의 업데이트 방정식
$$
w_j^{(\text {new })}=w_j^{(\text {old })}-\eta \frac{\partial}{\partial w_j^{\text {(old) }}} J(\mathbf{w})
$$
이 방정식은 개별 가중치 매개변수 \(w_j\)에 대한 업데이트 규칙을 보여줍니다. 여기서 \(w_j^{(\text {old })}\)는 업데이트 전의 가중치, \(w_j^{(\text {new })}\)는 업데이트 후의 가중치입니다. \(\frac{\partial}{\partial w_j^{\text {(old) }}} J(\mathbf{w})\)는 비용 함수를 가중치 매개변수 \(w_j\)에 대해 편미분한 것으로, 해당 가중치가 비용 함수에 미치는 영향의 변화율을 나타냅니다. 이 편미분 값에 학습률 \(\eta\)를 곱하여 기존 가중치에서 빼줌으로써, 비용 함수의 최소값을 향해 가중치를 업데이트합니다.
코드에서의 적용
위의 방정식들은 신경망 학습 시 가중치 업데이트에 사용됩니다. 특히, 신경망을 훈련할 때, 손실 함수의 그래디언트를 계산하고 이를 사용하여 가중치를 조정합니다. 예를 들어, 신경망에서 손실 함수로 크로스 엔트로피 또는 평균 제곱 오차(MSE)를 사용할 수 있습니다. 학습 과정에서는 이 손실 함수의 값을 최소화하기 위해 역전파 알고리즘을 사용하여 각 가중치에 대한 손실 함수의 그래디언트
를 계산하고, 이를 기반으로 가중치를 업데이트합니다.
가중치 업데이트는 신경망의 학습률과 손실 함수의 그래디언트에 따라 결정되며, 이 과정을 통해 모델의 성능을 점차
최적상태를 찾아갑니다