
갤러리 보기
갤러리 보기

샤를 조제프 민아르( 나폴레옹 모스크바 진군맵)
나폴레옹의 모스크바 진군은 1812년에 일어난 역사적인 사건으로, 나폴레옹 보나파르트의 프랑스 대군이 러시아 제국을 침공한 것을 말합니다. 이 사건은 나폴레옹 전쟁의 일환으로, 당시 유럽 대륙을 지배하던 나폴레옹의 군대가 러시아 깊숙이 진군하여 모스크바에 이르렀음에도 불구하고, 결국 실패로 귀결되었습니다.
그 중 나폴레옹의 모스크바 진군 시각화 예시는 복잡한 역사적 사건을 한눈에 이해하고, 그 시기의 전략적 결정들이 어떤 결과를 가져왔는지 직관적으로 이해할 수 있습니다.
참고자료
샤를 조제프 민아르
사진 : dwardtufte

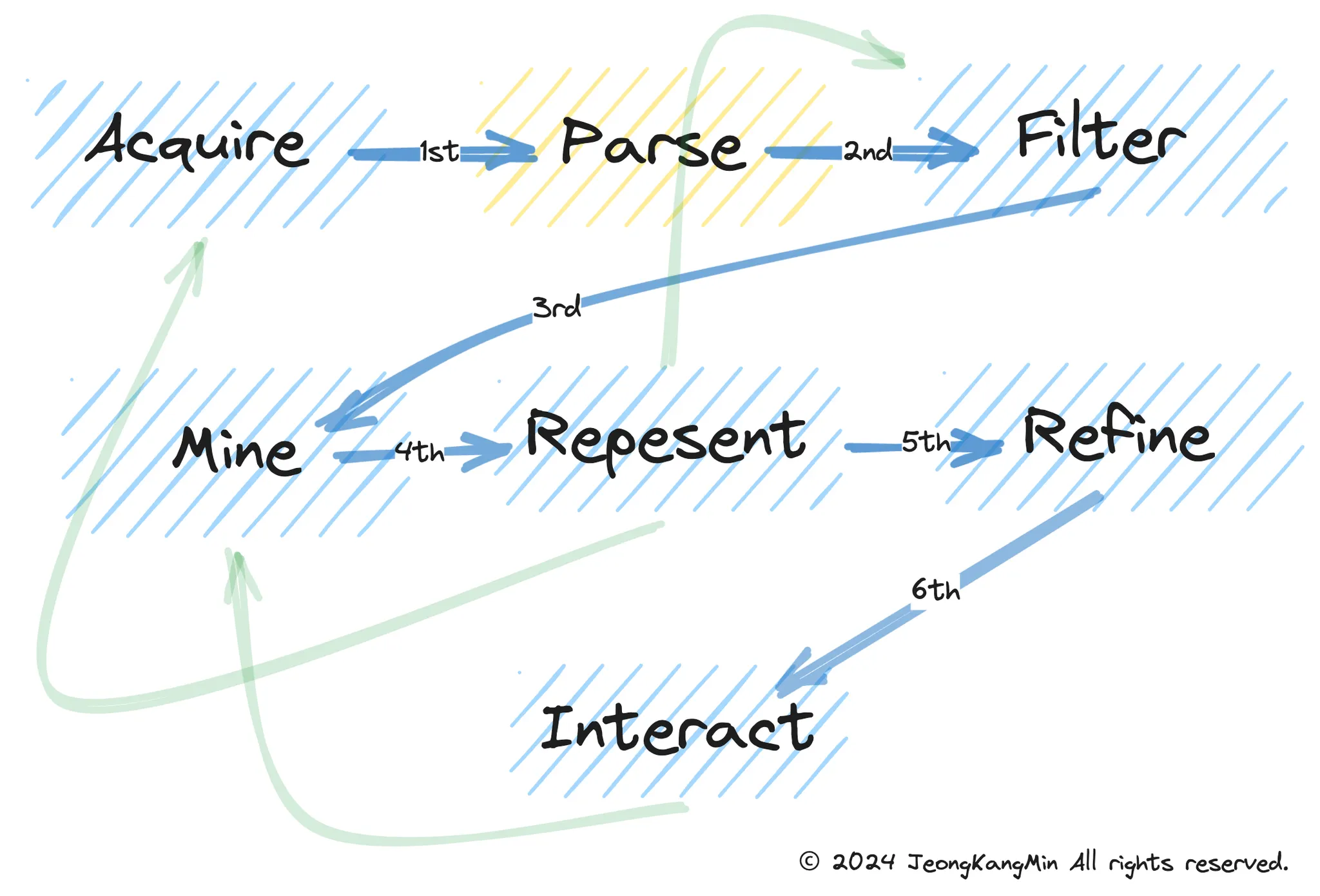
시각화의 시초 - 나폴레옹 진군맵



플로렌스 나이팅게일은 이탈리아 피렌체에서 태어난 영국 상류층 가정의 딸로, 교양 교육을 받으며 수학과 분석에 탁월한 재능을 보였습니다. 당시 보수적인 사회분위기 속에서 간호사라는 직업은 멸시받았으나, 병약한 이들을 돌보겠다는 신앙적 사명감을 가졌습니다. 나이팅게일은 가족의 반대를 무릅쓰고 자신의 길을 갔습니다.
나이팅게일의 시각적 도구는 공간-시간 데이터의 그래픽 표현에 있어 혁신적인 사례로, 위치를 명시적으로 표시하지 않고도 데이터의 시간적 변화와 패턴을 명확히 전달합니다. 명확한 메시지 전달을 위한 깔끔한 디자인과 혁신의 예로, 오늘날 데이터 시각화 및 커뮤니케이션에 많은 영감을 제공합니다.
참고자료 : 나이팅게일 위키

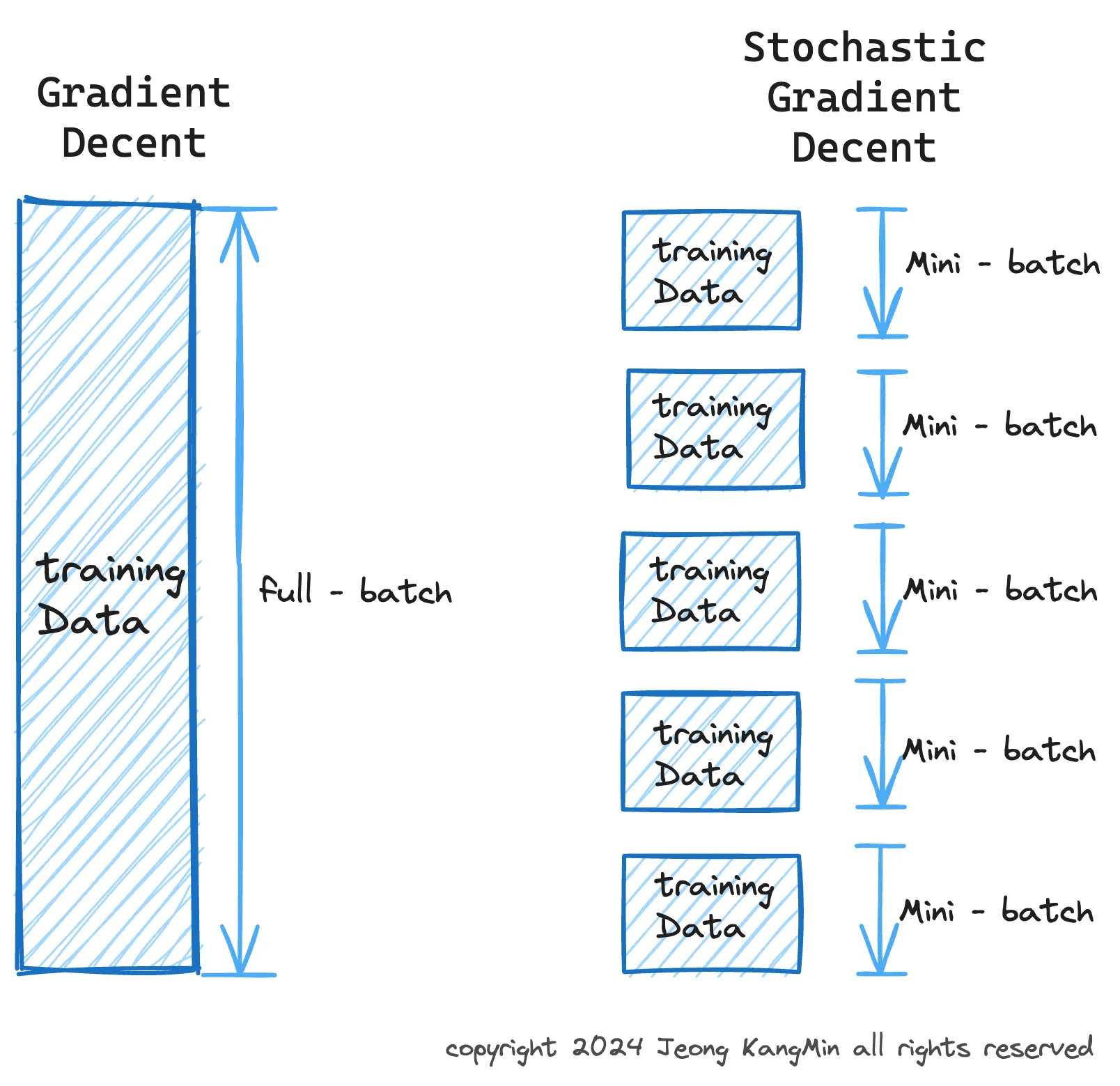
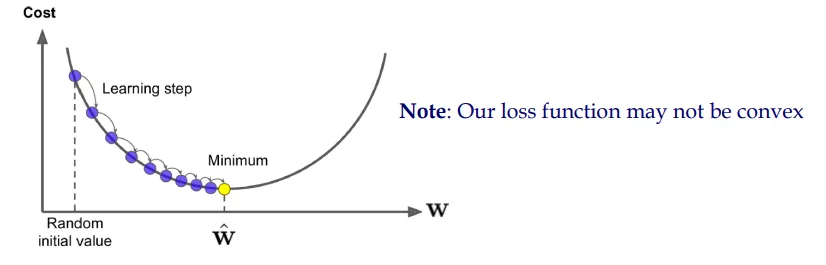
시각화의 시초 - 나이팅게일



갤러리 보기



갤러리 보기


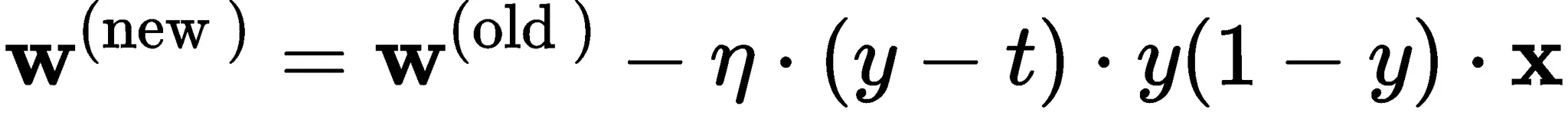
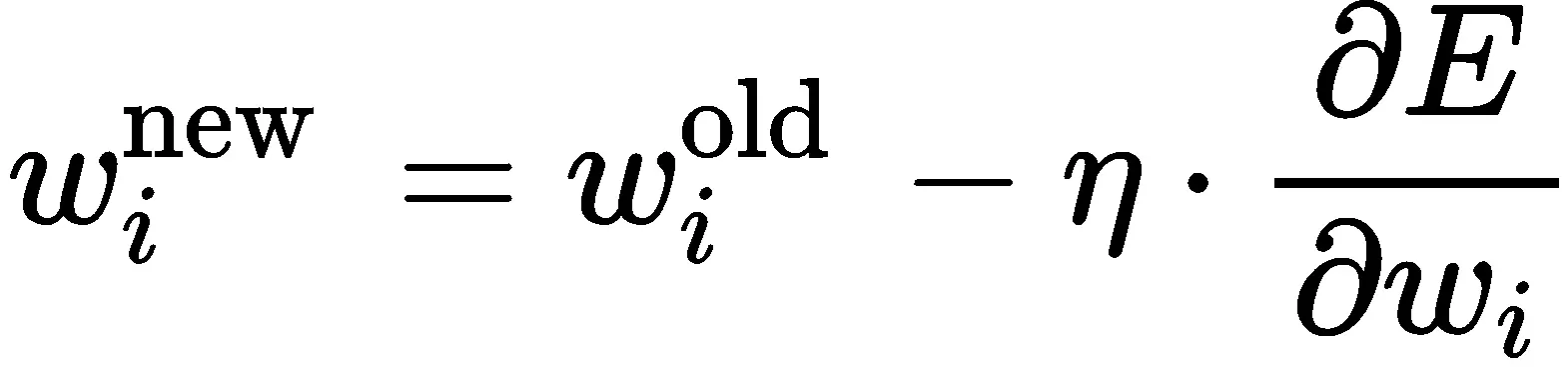
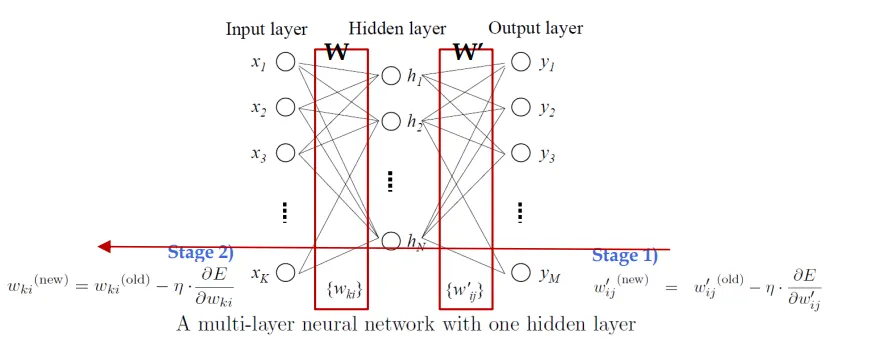
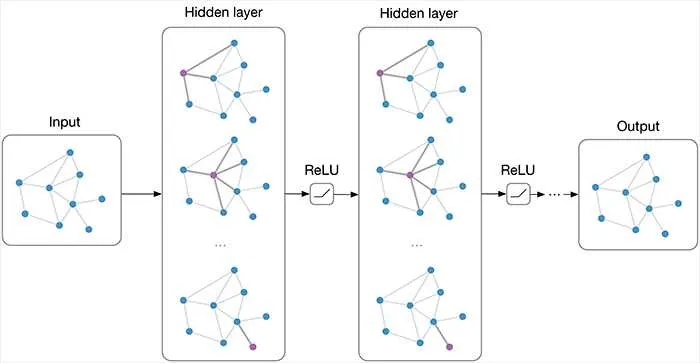
갤러리 보기