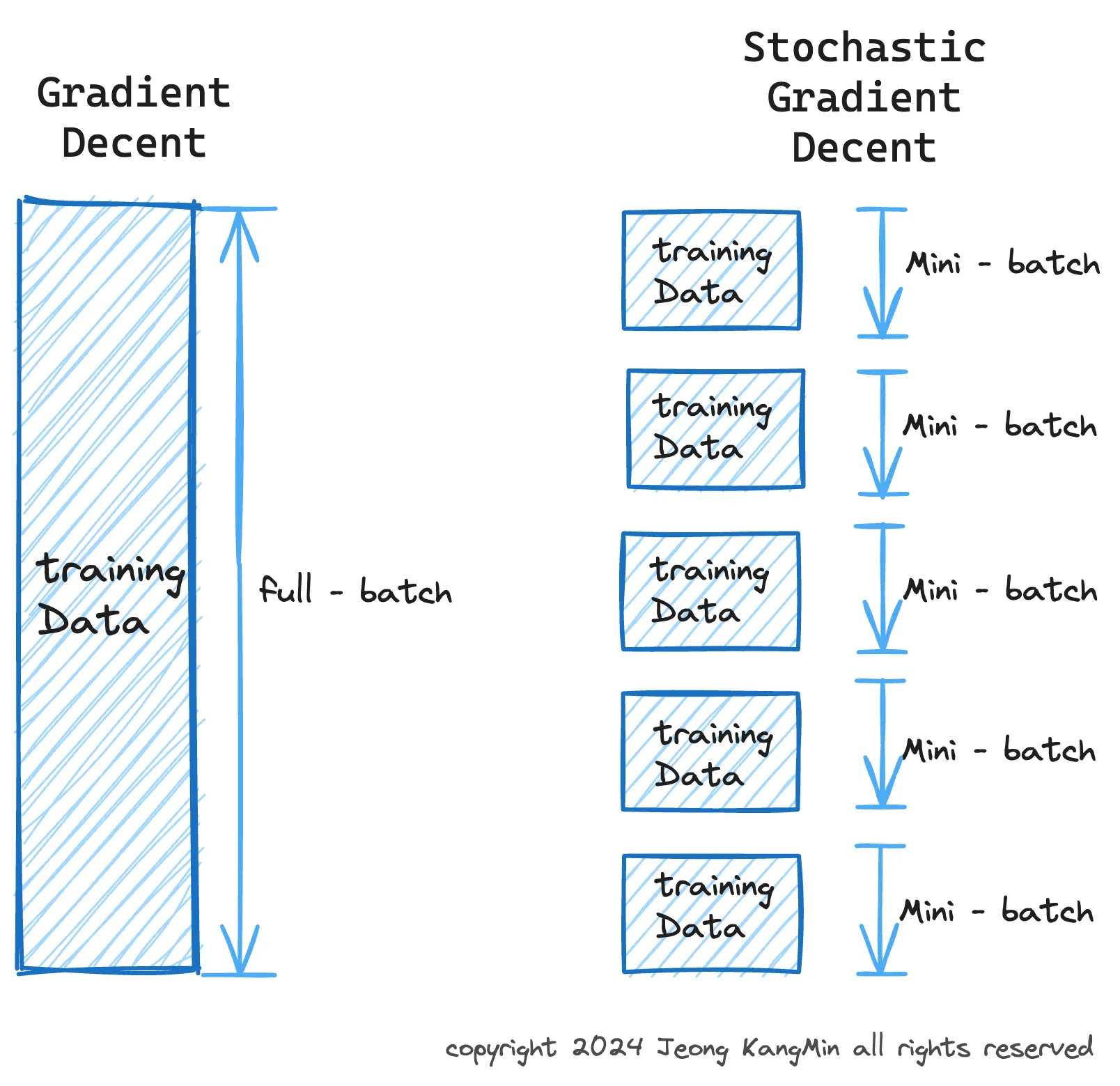
Q1. 왜 “미니”-배치를 사용하는가?
미니 배치 훈련은 배치 경사 하강법과 확률적 경사 하강법(SGD)의 극단 사이에서 균형을 이룹니다. 여기에는 그 사용 이유가 있습니다:
•
수렴: 미니 배치는 SGD에 비해 더 안정적인 수렴을 제공합니다. 왜냐하면 경사 업데이트가 하나의 샘플이 아닌 여러 샘플에 대해 평균화되기 때문에, 단일 예제로부터의 경사보다 덜 노이즈가 있기 때문입니다. 그러나, 전체 데이터셋을 사용하여 단일 업데이트를 계산하는 배치 경사 하강법보다 데이터 변동성에 더 민감합니다.
•
메모리 사용: 전체 데이터셋에 대한 훈련(배치 경사 하강법)은 메모리를 많이 소모하고 대규모 데이터셋에 대해 비현실적일 수 있습니다. 미니 배치는 모델을 데이터의 부분집합에 대해 훈련할 수 있게 하여 메모리 요구사항을 상당히 줄입니다.
•
병렬 처리: 미니 배치 훈련은 병렬 처리에 적합합니다. 현대 하드웨어(예: GPU)는 미니 배치에 대한 계산을 동시에 수행할 수 있어, 훈련 시간을 크게 단축시킬 수 있습니다.
•
정규화 효과: 미니 배치와 함께 훈련하는 것은 최적화 과정에 노이즈를 도입하여, 모델이 손실 함수의 날카로운 최소값에 정착하는 것을 방지할 수 있습니다. 이 노이즈는 일종의 정규화로 작용하여, 모델이 보지 못한 데이터에 대한 일반화를 potencially 개선할 수 있습니다.
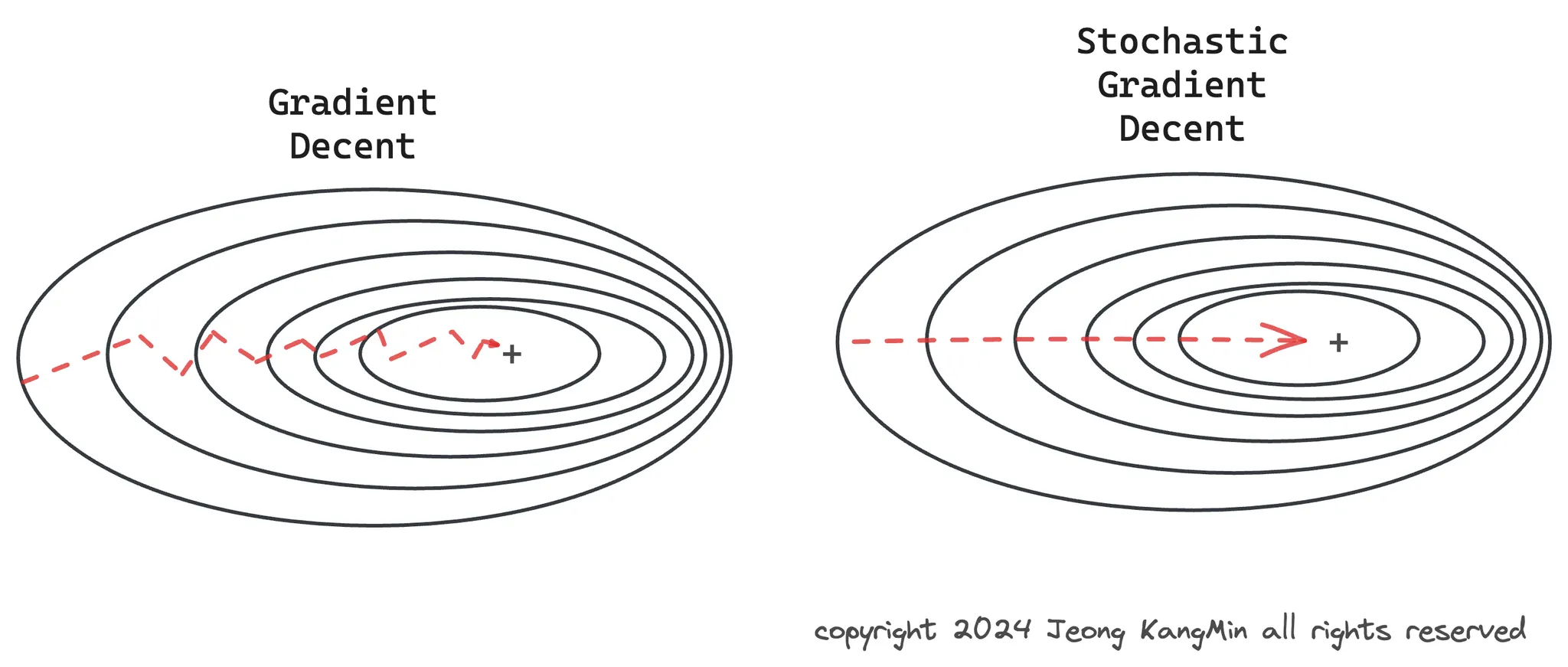
경사 하강법은 최적화 알고리즘의 한 형태로, 비용 함수(또는 손실 함수)의 최소값을 찾는 데 사용됩니다. 이 방법은 신경망 훈련에 널리 사용되며, 특히 배치 크기에 따라 다음과 같이 세 가지 주요 변형으로 분류됩니다:
1. (배치) 경사 하강법
•
정의: 배치 경사 하강법은 훈련 데이터 전체를 사용하여 각 반복에서 그라디언트(경사)를 계산합니다.
즉, 모델 업데이트를 위해 전체 데이터셋에 대한 비용 함수의 그라디언트를 한 번에 계산합니다.
•
장점: 그라디언트 계산이 안정적이며 노이즈가 적습니다.
이론적으로는 더 안정적인 수렴을 제공할 수 있습니다.
•
단점: 전체 데이터셋에 대한 그라디언트를 계산하기 때문에 계산 비용이 매우 높습니다.
특히 대규모 데이터셋에서는 메모리 문제가 발생할 수 있습니다.
또한, 매우 평평한 지역에서 느린 수렴이 문제가 될 수 있습니다.
2. 확률적 경사 하강법 (SGD)
•
정의: SGD는 훈련 샘플 하나를 사용하여 각 반복에서 그라디언트를 계산합니다.
이는 각 반복에서 하나의 데이터 포인트만을 사용해 모델을 업데이트합니다.
•
장점: 계산 효율성이 높고, 대규모 데이터셋에서도 사용할 수 있습니다.
또한, 노이즈가 많은 그라디언트로 인해 지역 최소값에서 벗어날 가능성이 높습니다.
•
단점: 그라디언트의 높은 변동성으로 인해 수렴 과정이 불안정할 수 있으며,
최소값에 도달하더라도 계속해서 진동할 수 있습니다.
3. 미니 배치 경사 하강법
•
정의: 미니 배치 경사 하강법은 배치 경사 하강법과 SGD의 절충안으로, 각 반복에서 소규모 데이터셋(미니 배치)을 사용하여 그라디언트를 계산합니다. 미니 배치의 크기는 일반적으로 2에서 수백 사이입니다.
•
장점: 더 안정적인 수렴과 함께 계산 효율성을 제공합니다.
GPU와 같은 하드웨어 가속을 통해 병렬 처리가 가능하며,
적절한 미니 배치 크기 선택으로 노이즈가 있는 그라디언트의 이점을 활용할 수 있습니다.
•
단점: 적절한 미니 배치 크기를 선택하는 것이 중요하며,
이는 문제에 따라 다를 수 있습니다.
너무 작거나 큰 미니 배치 크기는 성능에 부정적인 영향을 미칠 수 있습니다.
요약: 이 세 가지 방법은 모두 특정 상황에서 장단점을 가지며, 사용되는 데이터셋의 크기와 모델의 요구 사항에 따라 적절한 방법을 선택해야 합니다. 미니 배치 경사 하강법은 실제로 가장 널리