
Gallery

Transformer Architecture
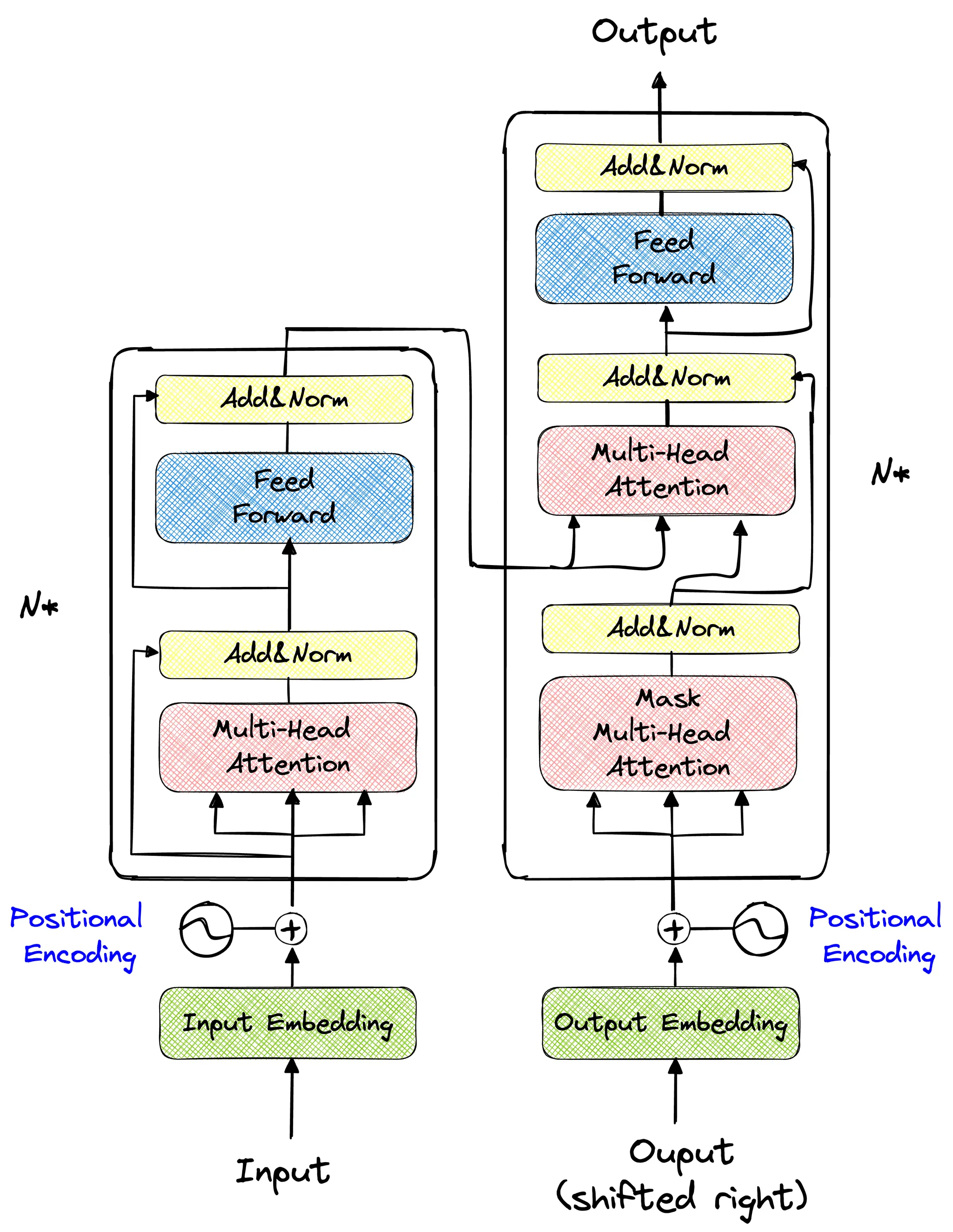
트랜스포머란?
기존의 seq2seq 모델의 한계

Transformer


Mamba: Linear-Time Sequence Modeling with Selective State Spaces

Chronos는 사전 훈련된 확률적 시계열 모델을 위한 간단하지만 효과적인 프레임워크입니다.
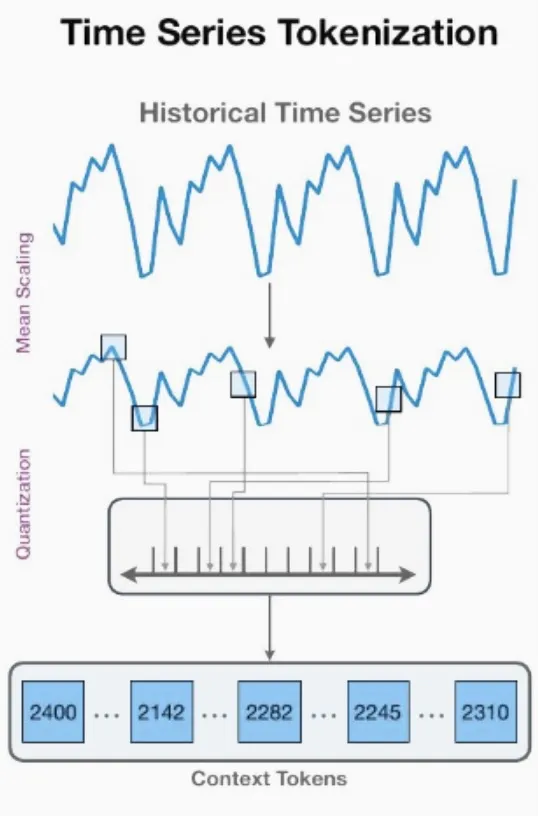
Chronos는 시계열 값을 스케일링과 양자화를 사용해 고정된 어휘집으로 토큰화하고, 이러한 토큰화된 시계열을 교차 엔트로피 손실을 통해 기존의 변환기 기반 언어 모델 구조에 훈련시킵니다.
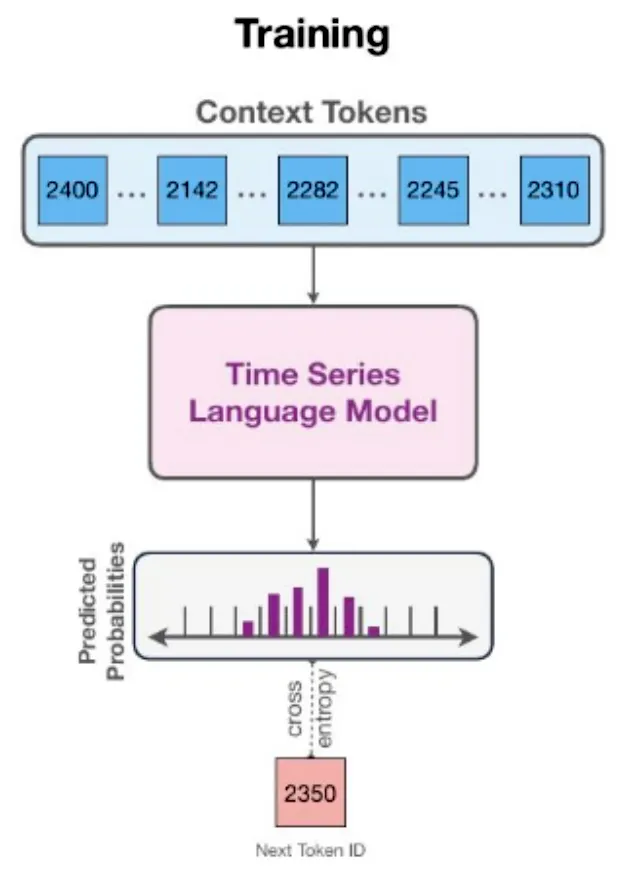
20M에서 710M에 이르는 T5 계열의 Chronos 모델을 대규모 공개 데이터셋 컬렉션과 일반화를 개선하기 위해 가우시안 프로세스를 통해 생성한 합성 데이터셋에 사전 훈련시켰습니다. 42개의 데이터셋으로 구성된 광범위한 벤치마크에서, 기존 로컬 모델과 딥러닝 통틀어, Chronos 모델이 훈련 데이터셋의 일부였던 데이터셋에서 다른 방법들을 크게 능가하고, 특정 데이터셋에만 훈련된 방법들과 비교했을 때 새로운 데이터셋에 대한 제로샷 성능이 비슷하거나 때로는 우수함을 보여줍니다.
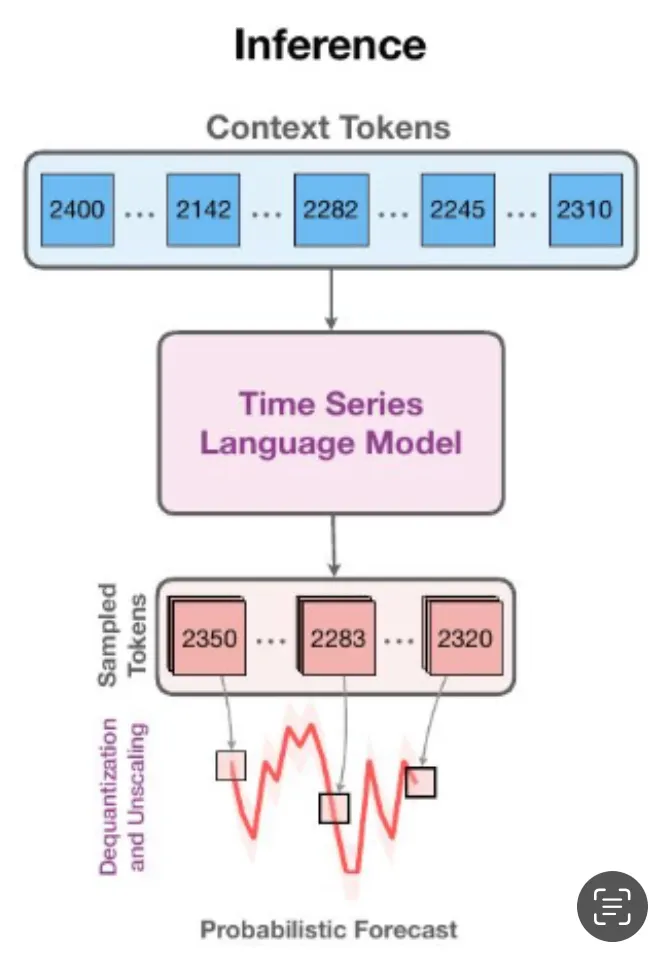
Chronos 모델이 다양한 도메인의 시계열 데이터를 활용하여 보이지 않는 예측 작업에 대한 제로샷 정확도를 향상시킬 수 있음을 보여주며, 사전 훈련된 모델을 예측 파이프라인을 크게 단순화할 수 있는 유망한 도구로 위치시킵니다.
Chronos: Learning the Language of Time Series
유튜브 CODE :  Google Colab
Google Colab
Google Colab
Pill of the week
This week is the time to give an overall view of the ARIMA model methodology, also called the Box-Jenkins method. We will link each step to previous issues of MLPills, so you can revise each step and become an ARIMA master!
ARIMA
Multivariate Time Series 데이터에서 자주 발생하는 결측값 문제가 시계열 데이터의 완전성을 해치고 효율적인 분석을 어렵게 한다는 문제를 다룹니다. 최근에는 딥러닝 기반의 보정 방법들이 손상된 시계열 데이터의 품질 개선에 있어 가시적인 성과를 보이고 있고, 이를 통해 Sub task의 성능이 크게 향상되었다고 합니다. 본 논문에서는 최근 제안된 딥러닝 보정 방법들에 대한 광범위한 조사를 실시합니다.
첫째로, 검토된 방법들을 분류하는 체계를 제안하고, 이 방법들의 장점과 단점을 강조하는 체계적 리뷰를 제공합니다. 이어서, 다양한 방법들을 실험하여 그들이 하위 작업에서 어떤 향상을 가져다주는지 비교합니다.
마지막으로, Multivariate Time Series 보정을 위한 미래 연구의 개방적인 주제들을 제시합니다. 이 연구의 모든 코드와 설정, 그리고 정기적으로 업데이트되는 다변량 시계열 보정 관련 논문 리스트는 GitHub 저장소에서 확인할 수 있습니다.
전통적으로 결측 데이터를 처리하기 위해 다양한 통계적 보정 방법들이 널리 사용되어 왔습니다. 이러한 방법들은 결측값을
•
통계치(예: 0값, 평균값, 마지막 관측값)
•
간단한 통계 모델들, ARIMA, ARFIMA, SARIMA 등으로 대체합니다.
•
또한, 회귀분석, K-최근접 이웃, 행렬 분해 등의 기계 학습 기법들이 다변량 시계열에서 결측값을 처리하기 위해 문헌에서 주목을 받았습니다.
이러한 접근법의 주요 구현에는 KNNI, TIDER, MICE 등이 포함됩니다. 통계 및 기계 학습 보정 방법들은 간단하고 효율적이지만, 시계열 데이터에 내재된 복잡한 시간적 관계와 변동 패턴을 포착하는 데에는 한계가 있어 성능이 제한적입니다.

KNNI, TIDER, MICE
KNNI (K-Nearest Neighbors Imputation)
•
정의: KNNI는 결측치를 가진 데이터 포인트와 가장 가까운 K개의 이웃 데이터 포인트를 기반으로 결측치를 추정하는 방법입니다. 이웃 데이터 포인트의 값들을 이용해 평균, 중앙값, 가중치 평균 등으로 결측값을 대체할 수 있습니다.
•
사용 분야: 다변량 데이터셋에서 특히 유용하며, 소규모에서 중규모 데이터셋의 결측치 처리에 적합합니다.
TIDER (Temporal Interpolation for Data-driven Emission Reduction)
•
정의: TIDER는 최근에 제안된 방법으로, 특히 시계열 데이터의 결측치를 보간하는 데 초점을 맞춥니다. 시간적 패턴과 동적인 변화를 고려하여 결측치를 예측하고 보완합니다.
•
사용 분야: 주로 환경 데이터나 기후 데이터에서 발생하는 시계열 결측치 처리에 사용됩니다.
MICE (Multivariate Imputation by Chained Equations)
•
정의: MICE는 다변량 데이터의 결측치를 처리하기 위해 연쇄 방정식을 사용하는 방법입니다. 각 결측치가 있는 변수를 대상으로 조건부 분포를 설정하고, 반복적인 절차를 통해 결측치를 예측합니다. 이 방법은 각 변수 간의 관계를 고려하여 보다 정확한 결측치 예측을 가능하게 합니다.
•
사용 분야: 의료, 사회 과학, 경제학 등 다양한 분야에서 널리 사용됩니다.
이 방법들은 각기 다른 접근 방식을 통해 결측치 문제를 해결하려고 하며, 사용되는 데이터의 종류와 결측치의 특성에 따라 적합한 방법을 선택할 수 있습니다.
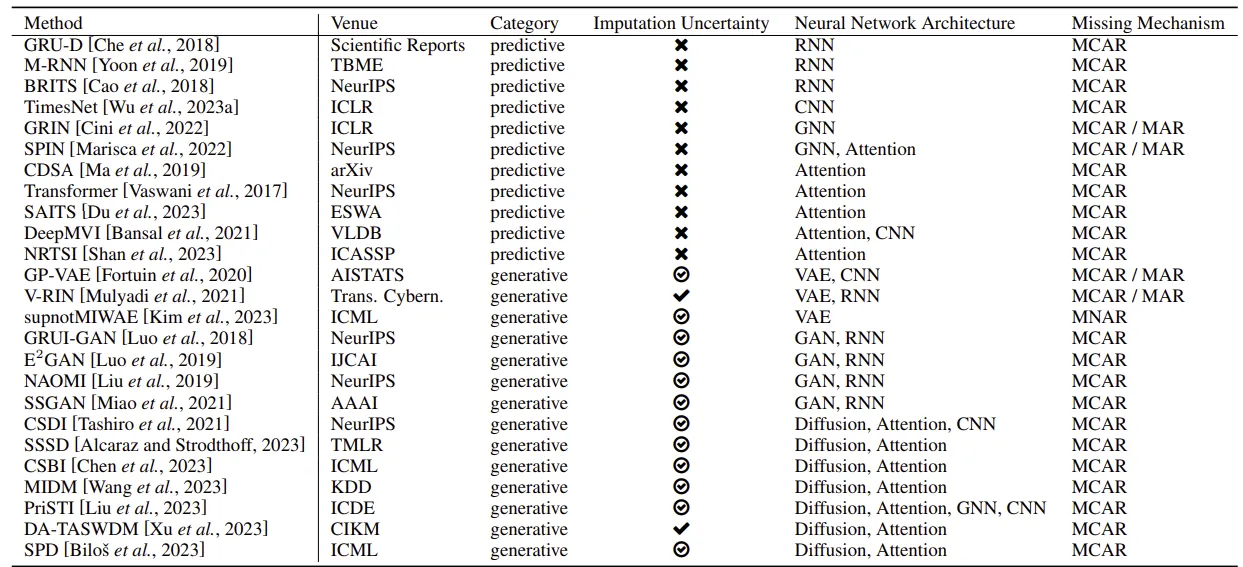
Deep Learning for Multivariate Time Series Imputation: A Survey
Gallery
CNN

RNN

LSTM

GRU
갤러리 보기
확률론은 여러 분야에서 광범위하게 활용되며, 그 중요성은 계속해서 증가하고 있습니다. 유전학, 물리학, 계량경제학, 금융, 역사학, 정치학 뿐만 아니라 인문학과 사회과학에서도 마찬가지입니다. 도박과 게임 또한 확률론이 중점적으로 다루는 주제 중 하나로, 역사적으로 페르마와 파스칼 같은 수학자들에 의해 연구되었습니다. 확률론은 불확실성을 계량화함으로써, 우리가 세계를 이해하는 데 중요한 도구입니다.
•
표본공간(sample space): 특정 시행에서 가능한 모든 결과의 집합을 의미합니다.
•
사건(event): 표본공간의 부분집합으로, 하나 이상의 결과를 포함할 수 있습니다.
확률의 기본 가정은 모든 사건이 발생할 확률이 동일하며, 표본공간이 유한하다는 것입니다. 이 가정은 모든 상황에 적용될 수 있는 것은 아니므로, 특정 상황에서는 이 가정에 기반한 확률을 적용하는 것이 부적절할 수 있습니다.
•
셈 원리(Counting Principle): 복잡한 확률 문제를 해결하기 위한 기본적인 원칙입니다.
•
곱의 법칙(Multiplication Rule): 여러 단계에 걸친 시행에서 각 단계에서 발생 가능한 경우의 수가 (n1,n2,...,nr)일 때, 전체 시행에서 발생 가능한 모든 경우의 수는 (n1×n2×...×nr)입니다.
•
이항계수(Binomial Coefficient): 크기가 \(n\)인 집합에서 크기가 \(k\)인 부분집합을 만들 수 있는 방법의 수입니다. 이는 (kn)=(n−k)!k!n! 로 표현됩니다.
순서와 복원 여부에 따라 다르게 적용되는 표본 추출 방법도 중요한 개념입니다. 이는 특정 상황에서 표본을 선택하는 방법을 정의하며, 확률론적 접근 방식에서 기본적인 역할을 합니다.
Probability and Counting