


Data Visualization Design Process
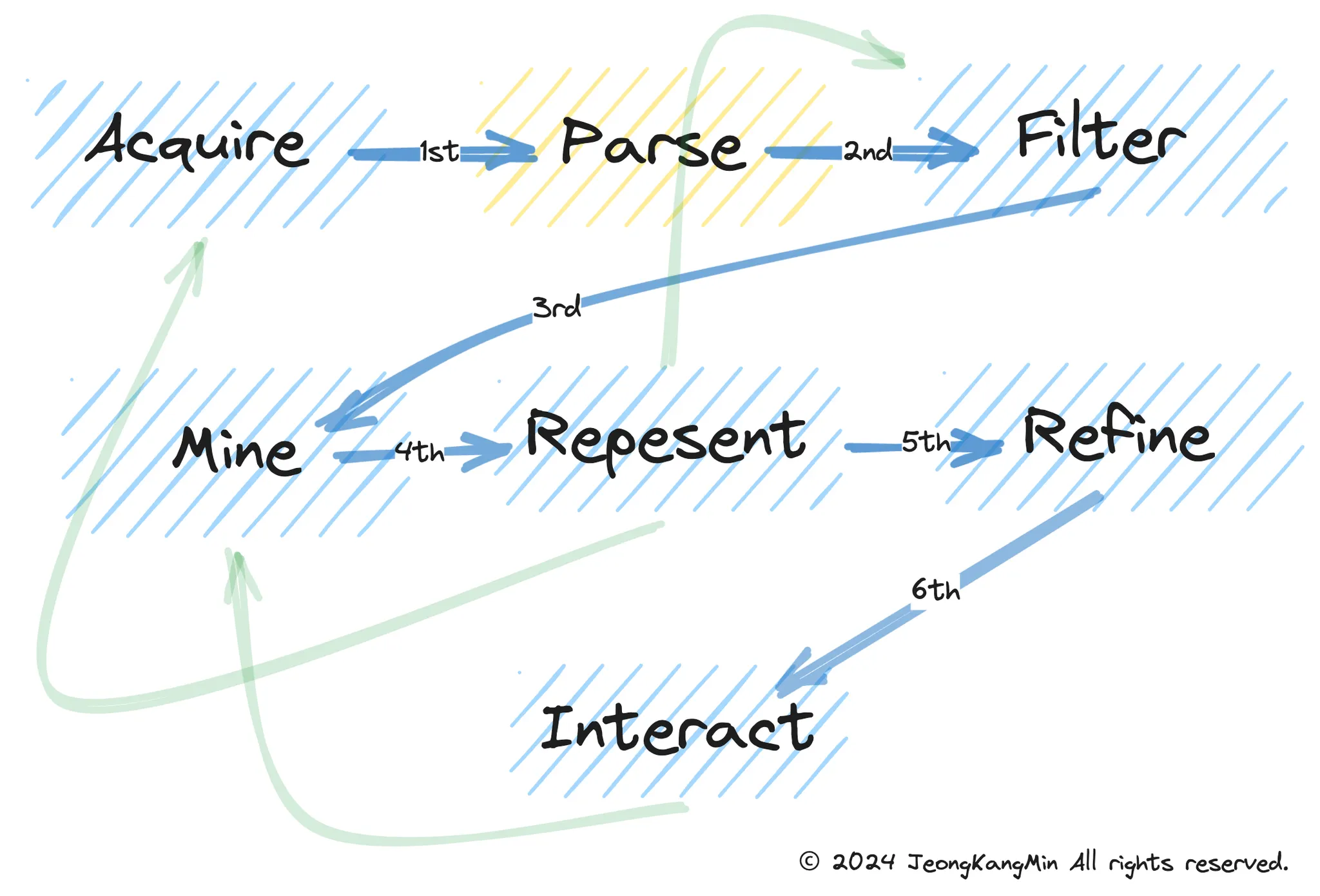
The Seven Stages of Data Visualization by Ben Fry
Ben Fry의 데이터 시각화 7단계는 데이터와 그 처리 과정을 통해 효과적인 시각화를 생성하기 위한 절차를 설명합니다. 이 단계들은 데이터 시각화 과정에서 중요한 역할을 하며, 각 단계는 다음과 같습니다:
1.
수집 (Acquire): 데이터를 수집하는 단계입니다. 여기서는 필요한 데이터를 모으고, 이 데이터가 어디에서 왔는지, 어떻게 수집되었는지를 이해하는 것이 중요합니다.
2.
구문 분석 (Parse): 수집한 데이터를 읽고 해석하는 단계입니다. 데이터 형식을 이해하고, 필요한 데이터 구조로 변환하는 작업을 포함합니다.
3.
필터 (Filter): 관련성이 떨어지거나 필요하지 않은 데이터를 제거하는 단계입니다. 이 과정을 통해 데이터 집합을 좀 더 관리하기 쉽고, 분석에 유용하게 만듭니다.
4.
마이닝 (Mine): 데이터에서 유용한 정보나 패턴을 추출하는 단계입니다. 통계적 방법, 데이터 마이닝 기술, 머신 러닝 알고리즘 등을 사용할 수 있습니다.
5.
표현 (Represent): 데이터를 시각적 형태로 표현하는 단계입니다. 차트, 그래프, 맵 등 다양한 시각화 기법을 사용하여 데이터를 표현할 수 있습니다.
6.
정제 (Refine): 시각화의 미적 요소를 개선하는 단계입니다. 색상, 레이아웃, 스케일 등을 조정하여 정보를 더 명확하고 이해하기 쉽게 만듭니다.
7.
상호작용 (Interact): 사용자가 시각화와 상호작용할 수 있도록 하는 단계입니다. 이를 통해 사용자는 데이터를 더 깊이 탐색하고, 다양한 관점에서 정보를 검토할 수 있습니다.
이 7단계 프로세스는 데이터 시각화를 통해 복잡한 데이터에서 유의미한 인사이트를 추출하고, 이해 관계자에게 효과적으로 전달하기 위한 기본적인 틀을 제공합니다. Ben Fry의 접근 방식은 데이터를 다루는 전체 프로세스를 아우르며, 각 단계는 데이터 시각화의 질과 효과를 최대화하는 데 중요한 역할을 합니다.